短视频平台如抖音、TikTok、YouTube等面临着海量用户生成内容的挑战,其中重复视频和搬运内容的检测已成为平台内容管理的核心技术问题。本报告将深入分析这些视频平台如何判断视频重复性和搬运行为,探讨所采用的算法技术,并通过具体实例详细解释其工作原理。
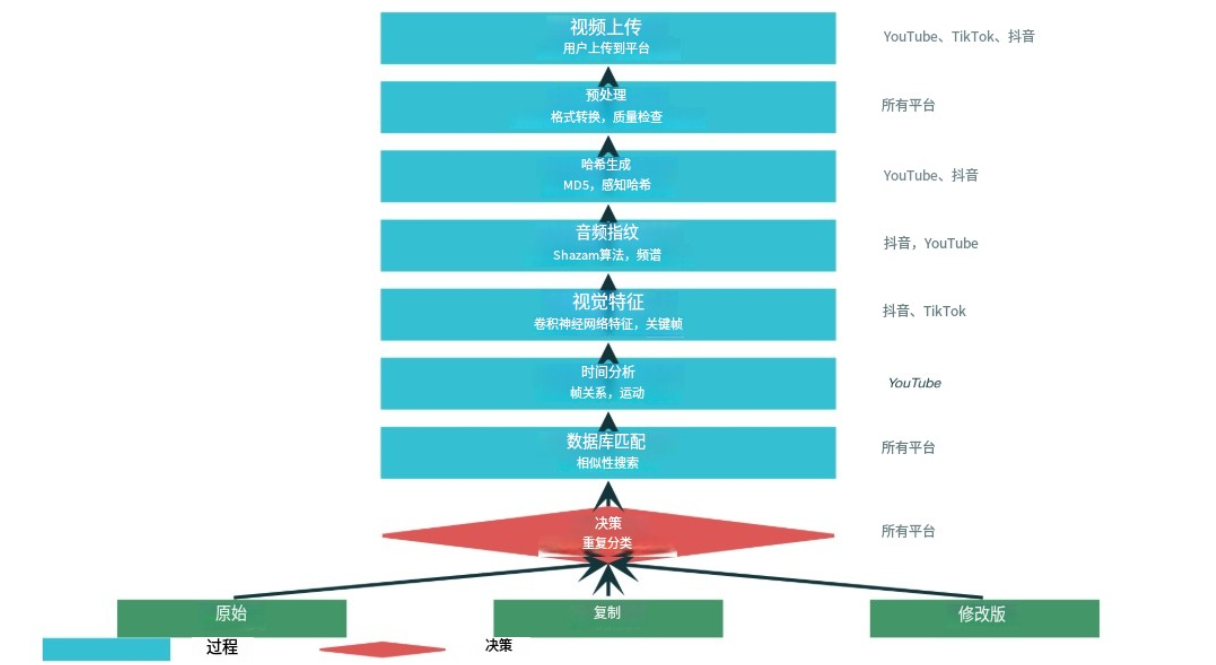
视频平台重复检测的基本方式
哈希比对技术
视频平台首先采用的是哈希比对技术,这是最基础但也是最快速的检测方法。平台会为每个上传的视频生成多种类型的哈希值:
MD5哈希是最简单的方法,通过计算视频文件的MD5值来识别完全相同的文件。当用户直接上传未经修改的视频时,系统可以在毫秒内通过MD5值匹配检测出重复内容。然而,这种方法无法检测经过任何编辑的视频,即使只是简单的格式转换或压缩也会产生完全不同的MD5值。
感知哈希技术则更为先进,能够检测视觉上相似但技术上不同的视频。系统会提取视频关键帧,通过DCT(离散余弦变换)或其他算法生成固定长度的哈希码。两个视频的感知哈希值通过汉明距离计算相似度,如果汉明距离小于设定阈值,则判定为重复内容。
音频指纹技术
音频指纹技术是视频平台检测搬运内容的重要手段,其中最著名的是基于Shazam算法的音频识别技术。该技术通过分析音频信号的频谱特征,生成独特的"音频指纹"来识别相同或相似的音频内容。
音频指纹的生成过程包括:首先对音频进行44.1kHz采样,然后通过**短时傅里叶变换(STFT)**生成频谱图。系统会从频谱图中提取峰值点,这些峰值代表了音频信号中最显著的频率成分。接下来,算法将这些峰值点配对形成"星座图",每个配对包含两个频率值和它们之间的时间差:。
视觉特征分析
现代视频平台广泛采用基于深度学习的视觉特征提取技术。通过卷积神经网络(CNN)等深度学习模型,系统可以提取视频帧的高层语义特征,这些特征能够捕捉视频的内容本质而非表面的像素信息。
这种方法的优势在于能够检测经过复杂编辑的视频,如调色、裁剪、添加水印、变速播放等。即使视频在像素层面发生了显著变化,其深层的语义特征往往保持相对稳定。
时序一致性检测
时序一致性分析是检测视频搬运的另一个重要维度。该技术通过分析视频帧之间的时间关系和动作连续性来识别重复内容。双层检测方法(Dual-level Detection)是这一领域的重要突破,包括视频编辑检测(VED)和帧场景检测(FSD)两个层面。
视频编辑检测模块首先判断视频是否经过编辑处理。对于未编辑的视频,系统使用随机向量作为描述符以节省计算资源。对于经过编辑的视频,系统会进行更深入的帧级分析,包括检测视频中是否存在多个场景的拼接。
核心算法技术详解
感知哈希算法家族
pHash(感知哈希)算法是视频重复检测中广泛使用的技术。该算法通过以下步骤生成哈希值:首先将图像缩放到32×32像素的标准尺寸,然后应用离散余弦变换(DCT)提取图像的频域特征。接下来,算法保留DCT系数的左上角8×8区域(低频部分),计算这些系数的均值,最后通过比较每个系数与均值的大小关系生成64位的二进制哈希码。
dHash(差异哈希)算法采用不同的策略,它将图像缩放到9×8像素,然后计算相邻像素之间的差异。如果某个像素比其右侧邻居更亮,则在哈希码中记录为1,否则记录为0。这种方法对图像的水平变化更为敏感,能够更好地捕捉图像的结构特征。
音频指纹算法深度剖析
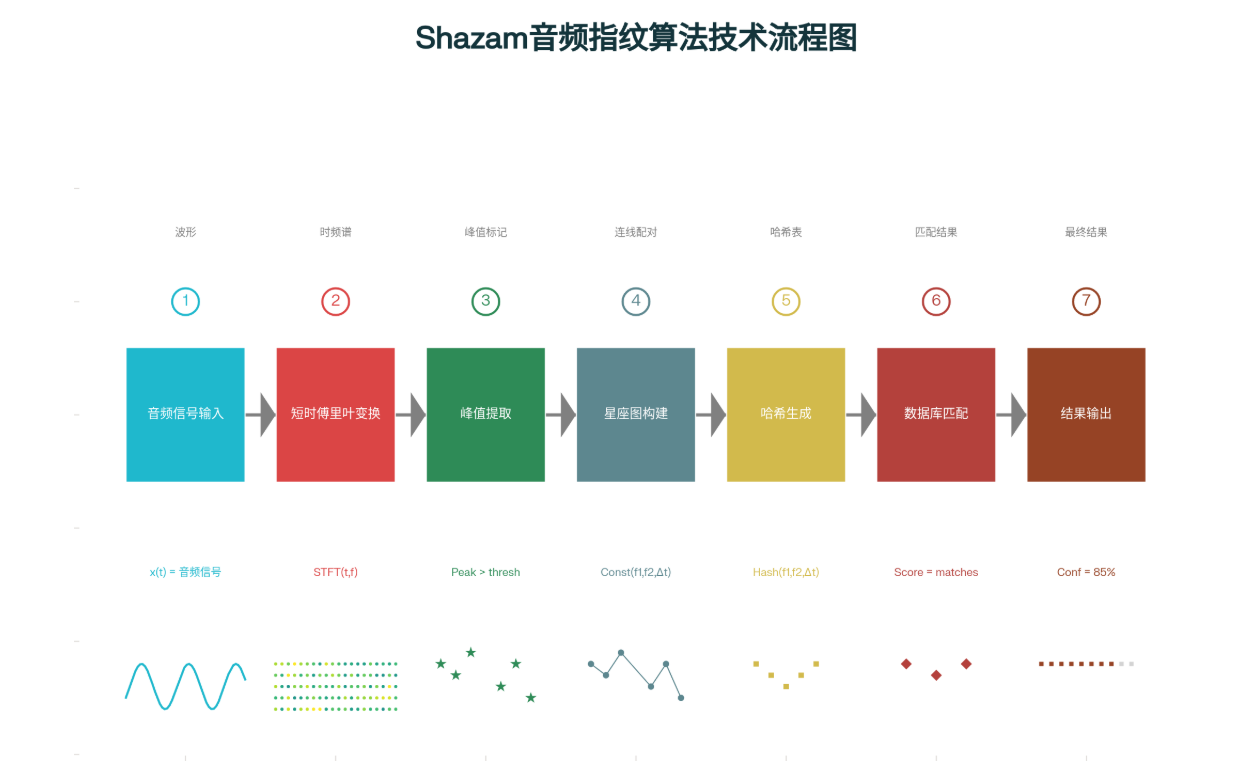
Shazam算法的核心在于星座图匹配技术。算法首先通过快速傅里叶变换(FFT)将时域音频信号转换为频域表示:
其中表示时间窗口内的音频采样点,是复指数函数。
峰值提取过程通过设定阈值来识别频谱图中的显著特征点:
STFT(t,f) & \text{如果} STFT(t,f) > threshold \\ 0 & \text{否则} \end{cases}$$ 星座图的构建是算法的关键步骤。系统将提取的峰值点进行配对,每个配对包含两个频率值和它们之间的时间差。这种配对方式使得算法对噪声和轻微的音频变形具有强大的鲁棒性。[4] 哈希生成过程将星座图信息转换为紧凑的数字指纹: $$Hash(P1, P2, \Delta t) = Hash(f1, f2, \Delta t)$$ 这个哈希值作为音频片段的唯一标识存储在数据库中,用于后续的快速匹配。[4] ### 深度学习特征提取自监督视频哈希(SSVH)技术代表了深度学习在视频重复检测中的最新应用。该技术采用分层二进制自编码器架构,包括编码器和三个解码器:前向分层二进制解码器、后向分层二进制解码器和全局分层二进制解码器。
编码器采用二进制LSTM(BLSTM)结构,能够直接生成二进制哈希码而无需后处理步骤。BLSTM的数据流遵循标准LSTM的模式,但在最后添加了符号函数来产生二进制输出。
为了解决二进制优化的NP困难问题,算法采用近似符号函数:
-1 & \text{当} h 1 \end{cases}$$ 这种近似方法允许梯度在反向传播过程中通过符号函数,使得整个网络可以端到端训练。[9] ### 时序一致性分析算法时序一致性重排算法是处理视频片段定位的核心技术。该算法首先通过关键点聚合和深度学习提取图像级特征,然后使用多重k-d树结构进行高效的KNN搜索,获得候选视频片段集合。
算法的创新点在于时序一致性剪枝步骤,通过分析候选片段的时间戳信息和序列ID,精确识别匹配片段及其在序列中的时间位置。这种方法能够在1百万帧的数据库中以83.96毫秒的速度完成单帧查询,在4.5百万帧数据库中的查询时间为462.59毫秒。
具体实现案例分析
YouTube Content ID系统
YouTube的Content ID系统是业界最成熟的版权检测技术之一。该系统采用多层次检测策略:
第一层是音频指纹匹配。系统为每个上传的视频生成音频指纹,并与庞大的参考数据库进行比对。即使音频经过音调变化、速度调整或添加背景噪音,系统仍能通过频谱分析检测出匹配内容。
第二层是视觉内容分析。系统使用深度学习模型分析视频的视觉特征,包括颜色分布、纹理模式、物体识别等。这些特征被编码为高维向量,通过余弦相似度计算来判断视频相似性。
第三层是元数据比对。系统会比较视频的标题、描述、标签等元数据信息,结合上述技术结果做出综合判断。
TikTok/抖音的双重检测机制
抖音和TikTok采用了双重检测机制来应对短视频的特殊性:
实时检测:在用户上传视频的过程中,系统会实时计算视频的感知哈希值和音频指纹。通过与现有数据库的快速比对,系统能在几秒钟内识别出明显的重复内容。
离线深度分析:对于通过实时检测的视频,系统会在后台进行更深入的分析。使用CNN模型提取语义特征,分析视频的内容创意度。对于检测到轻微修改的视频,系统会计算相似度分数,超过阈值的内容会被标记为疑似搬运。
实际检测效果数据
根据研究数据,现代音频指纹技术在理想条件下能达到100%的识别准确率:
-
1秒音频片段:识别准确率60%
-
2秒音频片段:识别准确率95.6%
-
5秒及以上:识别准确率100%
对于视频检测,双层检测方法在FIVR-200K数据集上实现了98.8%的召回率,在VCSL数据集上达到了94.1%的召回率。
感知哈希技术的性能表现为:
-
处理速度:单帧处理时间小于1毫秒
-
存储效率:每个视频帧仅需8字节哈希存储
-
检测精度:对于轻微修改的视频,检测准确率可达85-90%
挑战与技术发展趋势
对抗性攻击的应对
短视频领域的全球火爆,内容搬运者也在不断升级反检测手段。对抗性攻击是当前面临的主要挑战之一。攻击者通过在视频中添加微小的扰动信号,或者使用特定的编辑技巧,试图欺骗检测系统。
为了应对这些挑战,平台正在开发更加robust的检测算法。例如,使用拓扑指纹技术通过持续同调理论分析音频信号的拓扑结构,这种方法对时间拉伸和音调变化具有更强的鲁棒性。
多模态融合检测
现代视频检测系统越来越多地采用多模态融合策略。通过同时分析视频的视觉内容、音频特征、文本信息(如字幕、标题)和社交网络传播模式,系统能够构建更全面的内容指纹。
这种方法的优势在于:即使某一个模态被刻意修改,其他模态的特征仍能提供有效的检测信号。例如,即使视频画面被大幅修改,其音频特征和传播模式可能仍然暴露其搬运本质。
边缘计算优化
未来,视频检测正在向实时化和轻量化方向发展。新的算法设计重点关注:
计算效率:开发能在移动设备上运行的轻量级检测算法,减少对云端服务的依赖。
实时性:实现视频上传过程中的实时检测,而非传统的后处理模式。
隐私保护:在保护用户隐私的前提下进行内容检测,避免原始视频内容的泄露。
算法性能对比
不同检测算法具有各自的优势和适用场景:
MD5哈希适用于检测完全相同的文件,具有极高的速度和准确性,但无法处理任何形式的修改。
感知哈希在速度和鲁棒性之间取得了良好的平衡,适合检测轻微修改的内容,是大多数平台的首选技术。
音频指纹对音频内容的检测精度极高,即使在有背景噪音的情况下仍能保持良好性能,但计算复杂度相对较高。
深度学习方法能够理解视频的语义内容,对复杂编辑具有强大的检测能力,但需要大量的计算资源和训练数据。
时序分析擅长检测视频片段的拼接和重组,但处理速度相对较慢,通常作为二级验证手段使用。
在实际应用中,视频平台通常采用多算法融合的策略,根据视频的特点和检测需求动态选择最适合的算法组合。这种分层检测架构既保证了检测的全面性,又兼顾了计算效率和成本控制。
写在最后
当前主流的技术路线包括感知哈希、音频指纹、深度学习特征提取和时序一致性分析等,每种技术都有其独特的优势和适用场景。随着人工智能技术的不断发展,未来的检测系统将更加智能化、实时化和精准化,同时也需要在技术进步和用户体验之间找到更好的平衡点。