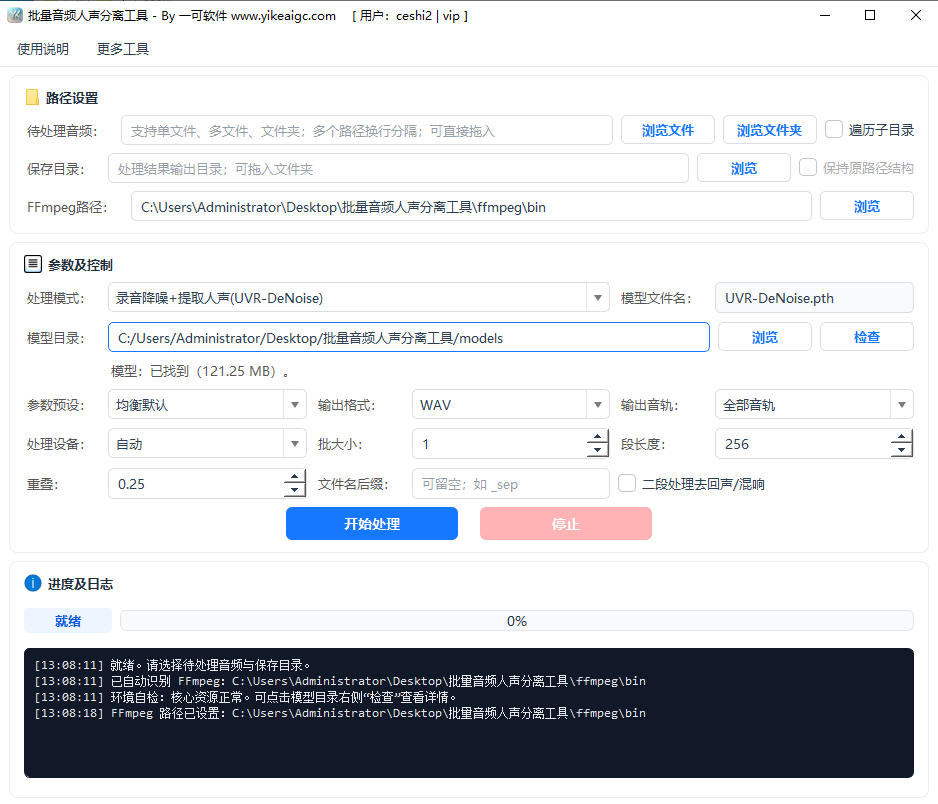
批量分离音乐人声与伴奏,支持录音降噪、去回声去混响提取人声,本地离线处理。
如无法加载或使用,请下载本地工具:https://tools.yikeaigc.com/
由于人声分离的 AI 模型推理需要消耗大量的计算资源,为了提供更稳定、高效的处理体验,此功能仅提供 Windows 桌面客户端版本。
免费注册-登录后,您可以免费使用本站提供的所有工具!
通过声纹指纹比对,在海量音频中自动找出重复及近似音频,支...
批量为视频和音频文件变声,内置多种变声预设,支持自定义变...
智能文字转语音合成,支持多种语音角色、情感调节、背景音乐...
为音频添加专业淡入淡出效果,支持四种曲线类型,实时预览,...
专业音频失真处理,支持软削波、硬削波、过载、模糊四种失真...
在线调节音频左右声道平衡,支持声道交换、独立音量控制,适...
自动检测并移除音频中的静音段和气口空隙,支持批量处理多种...
批量去除音频的底噪、电流声、风噪,并支持去混响、回声及人...
批量分析音频视频文件时长信息,支持按时长范围筛选,可导出...
批量检测音频采样率、削波、爆音、静音、响度与信噪比等指标...