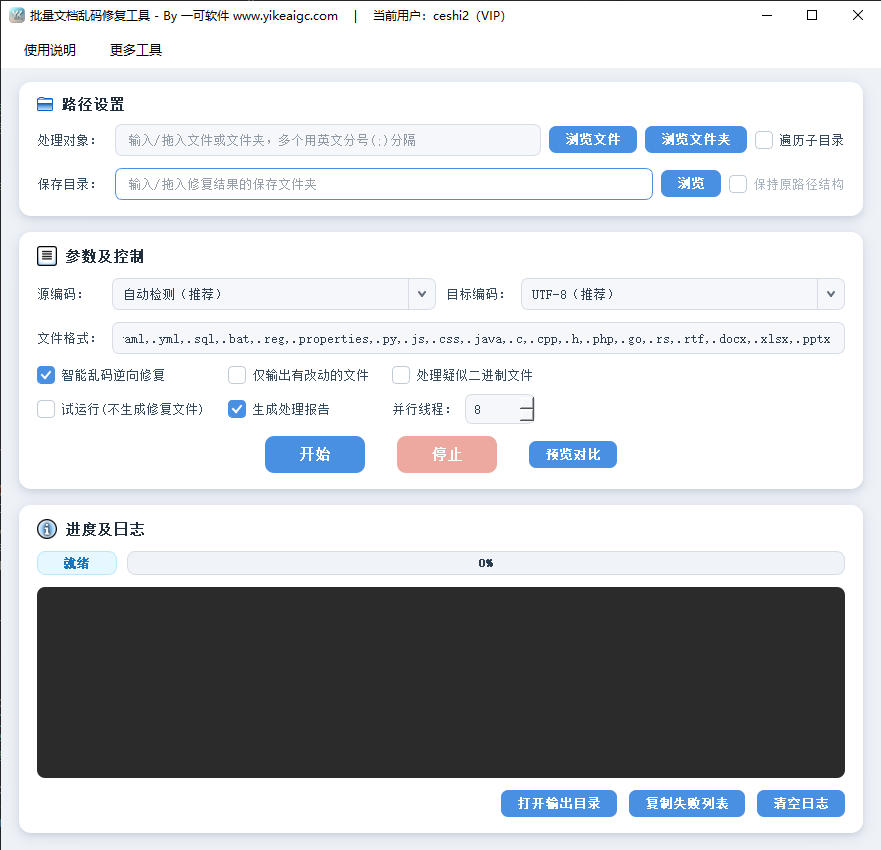
自动检测并还原 TXT、字幕、Word、Excel、PPT 等文档的中文乱码,支持多编码批量转换处理
如无法加载或使用,请下载本地工具:https://tools.yikeaigc.com/
由于乱码逆向还原与多编码智能检测需要消耗较多的计算资源,为了提供更稳定、高效的处理体验,此功能仅提供 Windows 桌面客户端版本。
免费注册-登录后,您可以免费使用本站提供的所有工具!
统计文本段落、句子、词数与字符,支持批量与多格式
根据文件名相似度对TXT/HTML文件分组,并依据字数、句子数等...
在线删除PDF文件中任意一个或多个页面,支持单文件可视化操作...
专业的在线列表差异对比工具,支持单个和批量模式,快速识别...
智能压缩PDF文件大小,支持批量处理和多级压缩强度,有效减少...
批量清理文本中的零宽空格、零宽连接符等隐藏字符(文本水印...
批量压缩Word和Excel文档中的内嵌图片,支持调节JPEG质量、PN...
为PDF文件的每一页或指定页面范围,在固定或随机位置加盖图片...
批量删除Word、PDF、PPT文档的指定页面,支持多种页面选择方式
批量互转 SRT、VTT、ASS、LRC、TXT 字幕格式,支持时间轴偏移...