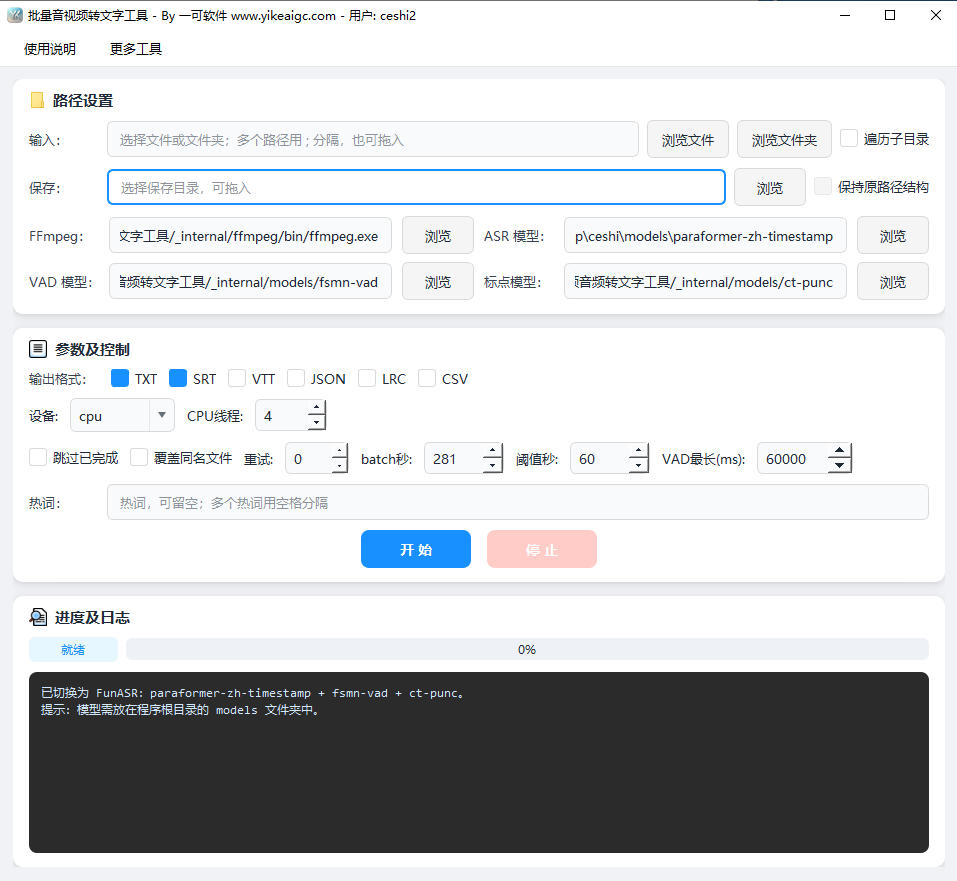
批量将视频和音频文件离线识别为文字,一键导出TXT、SRT、VTT、JSON、LRC、CSV多种字幕与文本格式。
如无法加载或使用,请下载本地工具:https://tools.yikeaigc.com/
由于离线语音识别模型加载与音视频解码需要消耗大量的计算资源,为了提供更稳定、高效的处理体验,此功能仅提供 Windows 桌面客户端版本。
免费注册-登录后,您可以免费使用本站提供的所有工具!
制作逐字符显示的打字机动画效果,支持自定义文字、速度、颜...
批量调整视频和音频音量,支持倍数、dB、LUFS响度标准化、峰...
批量调节视频亮度对比度饱和度色温,支持多种滤镜风格预设一...
批量将图片合成 MP4 视频,支持转场特效、背景音乐、字幕水印...
专业的视频宽高比计算器和调整工具,支持多种常用比例预设,...
智能匹配字幕关键词与本地素材,自动裁剪拼接生成视频,支持B...
智能删除视频音频中的静音片段,保持画面不变,让视频内容更...
智能检测并裁剪视频片头片尾,支持单个、多个及文件夹批量去...
批量从视频中提取帧图片,支持按时间或帧数间隔提取,可自定...
批量为MP4视频添加图片水印,支持固定/随机位置、透明度调节...