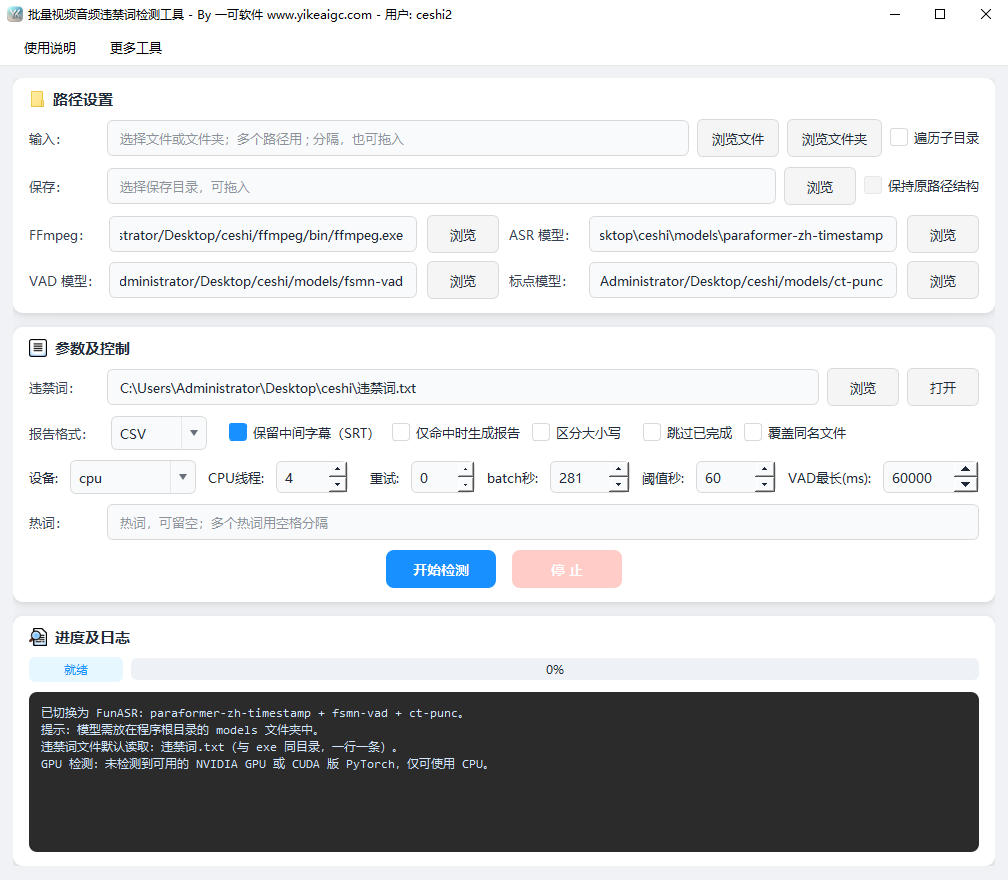
批量识别本地音视频内容,自动生成时间轴字幕并对照违禁词清单进行扫描,命中后输出详细报告,方便审核与整改。
如无法加载或使用,请下载本地工具:https://tools.yikeaigc.com/
由于本地语音识别和违禁词比对需要消耗较多 CPU 与显存资源,并依赖 FunASR 等离线模型,为了提供更稳定、可靠的处理体验,此功能仅提供 Windows 桌面客户端版本。
免费注册-登录后,您可以免费使用本站提供的所有工具!
批量为MP4视频添加图片水印,支持固定/随机位置、透明度调节...
批量去除视频开头和结尾指定时长,支持精确到秒的剪辑,可自...
批量去除视频声音或调整音量,支持MP4、AVI、MOV等格式,可完...
批量调节视频亮度对比度饱和度色温,支持多种滤镜风格预设一...
从视频文件中提取音频,支持MP4、AVI、MOV等格式,可输出MP3...
批量调整视频和音频音量,支持倍数、dB、LUFS响度标准化、峰...
智能匹配字幕关键词与本地素材,自动裁剪拼接生成视频,支持B...
支持多种视频格式在线转换分辨率,提供常用预设和自定义分辨...
批量处理视频素材,支持镜像、画中画、缩放、变速、抽帧等多...
制作逐字符显示的打字机动画效果,支持自定义文字、速度、颜...